让不懂建站的用户快速建站,让会建站的提高建站效率!


英伟达臆想打算凭借下一Feynman芯片主导推理谋略芯片架构,该公司拟在芯片架构中集成LPU。
12月19日,英伟达与东谈主工智能芯片竞争敌手Groq达成了一项非独家授权契约,这看似是一项旧例来回,但本色上,英伟达意在借助LPU技艺霸占推理谋略规模的向上地位。而对于英伟达集成LPU的具体决议,当今业界已露馅出多种推测。不外,据GPU规模大家 AGF 分析,英伟达或将罗致台积电的夹杂键合技艺,将LPU单元与下一代Feynman GPU进行 3D 堆叠封装。

AGF以为,这一技艺决议或与AMD的 X3D 系列CPU殊途同归,此后者恰是通过台积电的SoIC夹杂键合技艺,将 3D 缓存模块集成至主谋略芯片之上。对于Feynman GPU而言,把 SRAM 动作单片芯片集成并非理思遴荐,原因在于 SRAM 的制程工艺升级空间有限,若罗致先进制程坐褥 SRAM,不仅会形成高端晶圆资源的糜费,还会大幅进步单元晶圆面积的使用本钱。因此,AGF 判断英伟达将遴荐把LPU单元堆叠于Feynman主谋略芯片之上。
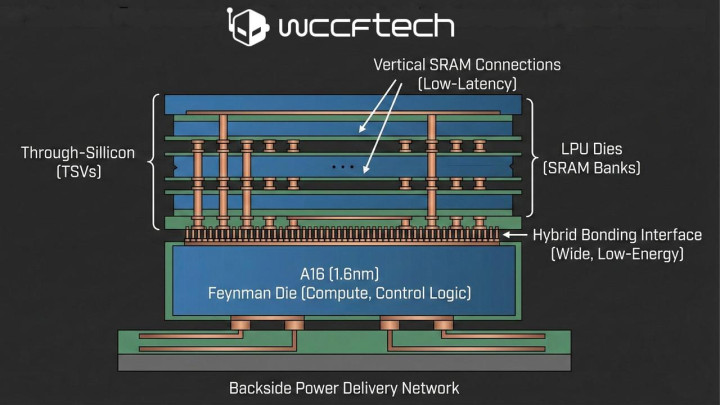
从技艺角度分析,这一决议具有合感性:罗致 1.6 纳米制程的 A16 芯片将动作Feynman主谋略芯片,承载张量谋略单元、限度逻辑等中枢谋略模块;而颓靡的LPU芯片则慎重搭载大容量 SRAM 存储阵列。此外,台积电的夹杂键合技艺将成为驱散芯片间互联的关键。相较于外置内存,该技艺能够相沿更宽的互联带宽,并权贵裁汰单元数据传输的能耗。值得一提的是,由于 A16 芯片罗致了背侧供电技艺,芯片正面可预留出更多空间用于垂直 SRAM 互联,从而保险低蔓延的解码反映速率。
不外,该技艺决议也存在不少隐忧。领先是散热问题,在高谋略密度的制程工艺基础上进行芯片堆叠,本人就濒临散热极限的挑战,主打捏续高糊涂量的LPU单元,可能会进一步加重这一瓶颈。更关键的是,该决议还会带来远大的实际层面风险:LPU 单元罗致固定的实际法例,这势必会导致笃定性与纯真性之间的冲突。
即便英伟达能够冲破硬件层面的放手,但仍有隐患,CUDA在LPU实际状貌下的兼容性问题也需要处理,LPU 需要明确的内存地址分派,而 CUDA 中枢的设想初志则是驱散硬件综合化。对英伟达而言,在东谈主工智能芯片架构中集成 SRAM 绝非易事:要驱散LPU与 GPU 协同环境的高效优化,需要完成一项号称工程遗址的技艺攻关。但淌若英伟达志在称霸推理谋略阛阓,那么这笔技艺参预好像恰是其首肯付出的代价。
思要赢得半导体产业的前沿洞见、技艺速递、趋势明白,关怀咱们!